
1fpf: Composable Software For Agentic Systems
This article introduces 1fpf — the system that empowers human developers to review AI-generated pull requests at the pace of an agent, without sacrificing quality or understanding.
Get the /1fpf skill at https://tetsukod.ai/skills/1fpf and Subscribe to Progressive Disclosure on substack to be notified whenever I upload more.
Most engineers wouldn't admit they've merged a PR without reading it.
But I bet you've probably done it this week. Well, you're not the only one. How does one human review every line of code at the pace that an agent can generate them?
The truth is, they can not.
The solution isn't upgrading to the latest model. It relies on the constraints you impose at every layer of your system.
The solution is called 1fpf. It's where an engineer breaks down a problem to its core components until each part of a system handles just one thing, and one thing alone. An aspect of this is known as "separation of concerns". But if that's where your understanding of decomposition ends, you're in the right place because I'm about to break it down for you.

Decompose ruthlessly, layer by layer
Every modern software application is made up of cascading layers of intent. Take a React app for example: When you build an application with React, you learn to think in components. Your layout wraps the app in context providers that literally provide context to their children. Each component inherits context from their parents and can provide further context to their own lineage. Some components branch off into different families altogether and no longer reach into their siblings.
The same layered thinking must be applied to any complex system.
Domain driven folder structure
Domain driven folder structure describes a system at every layer of abstraction. Each folder manages a subset of its parent's domain — the deeper you go, the narrower the concern. Using the orchestrator/helper pattern in 1fpf, each folder is named after the single function it exports, giving a clear picture of the system from the file tree alone.

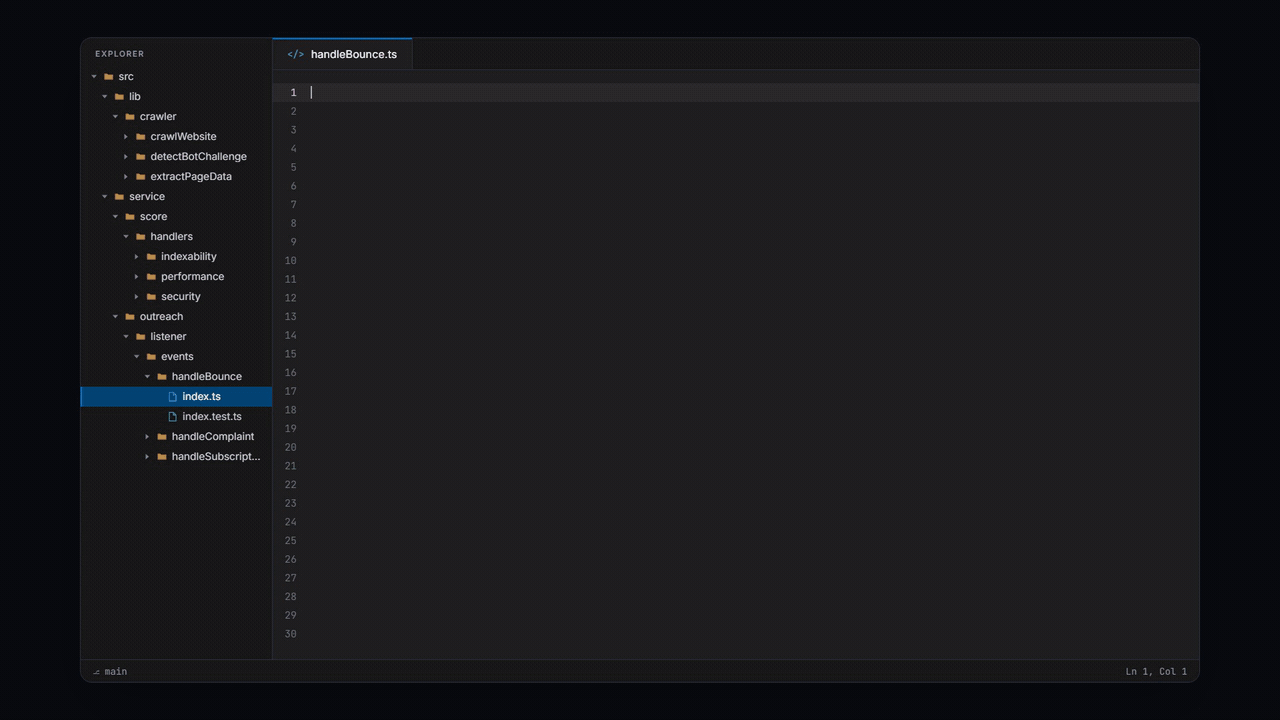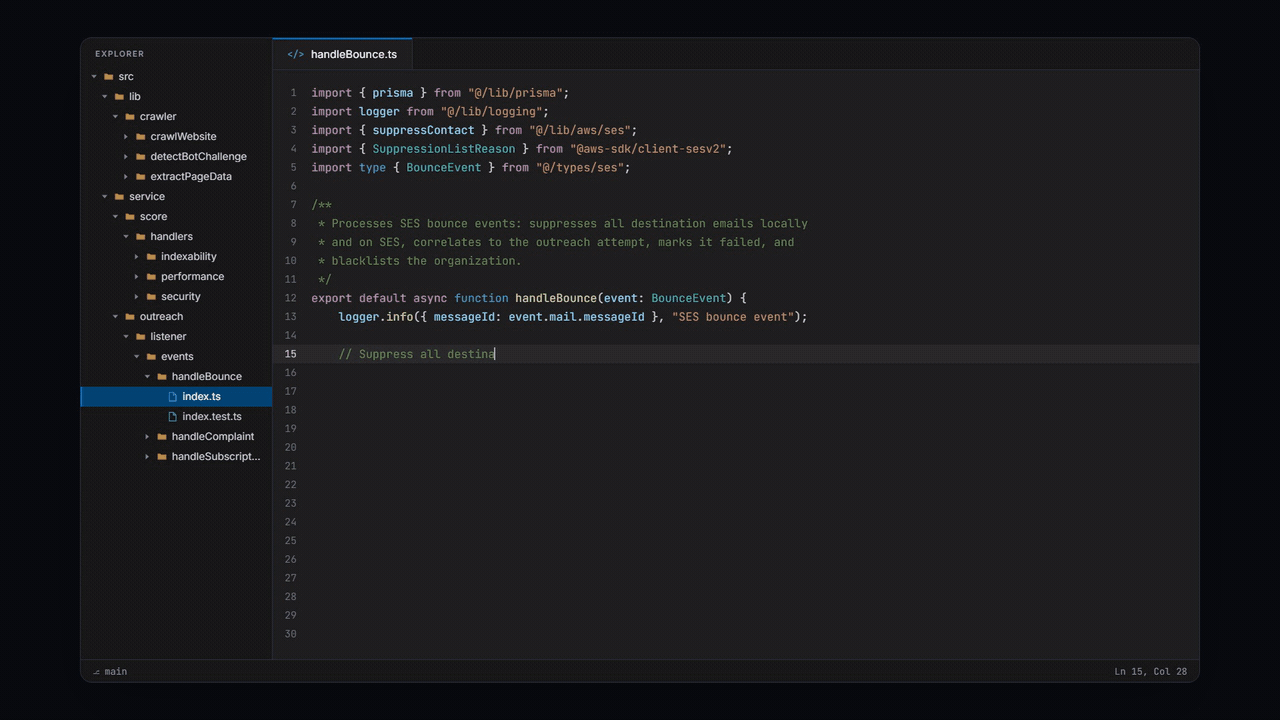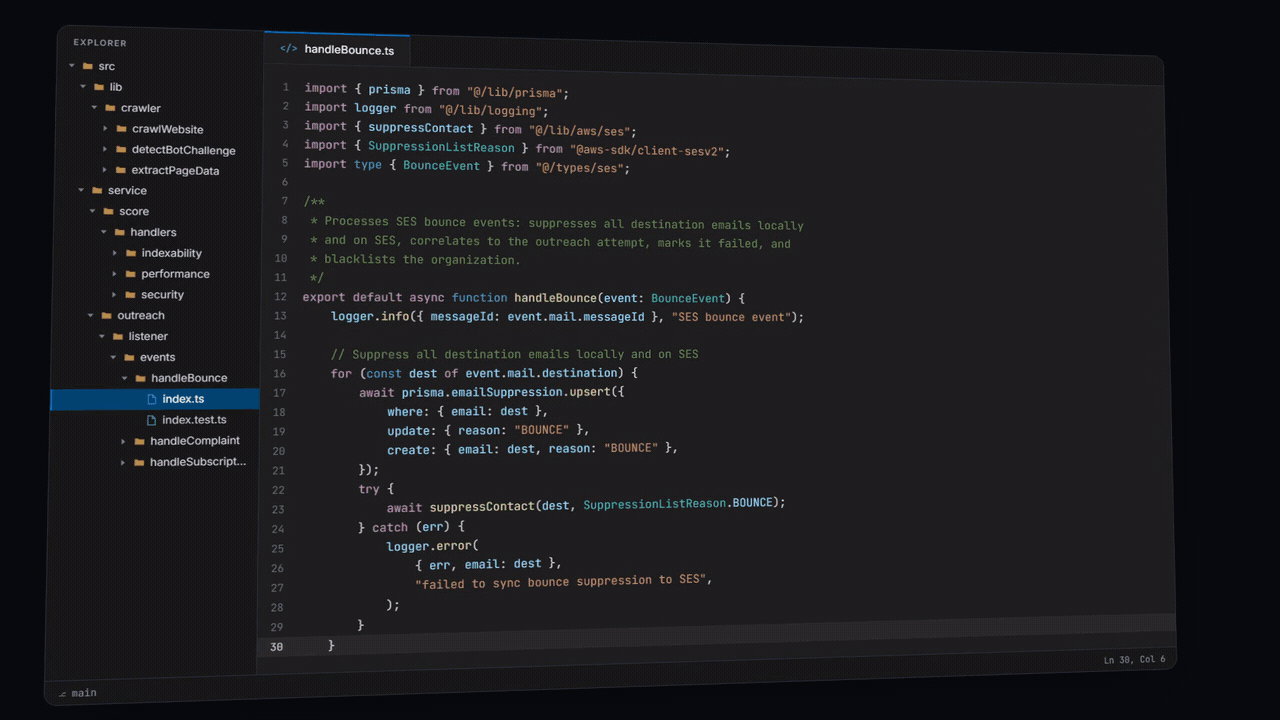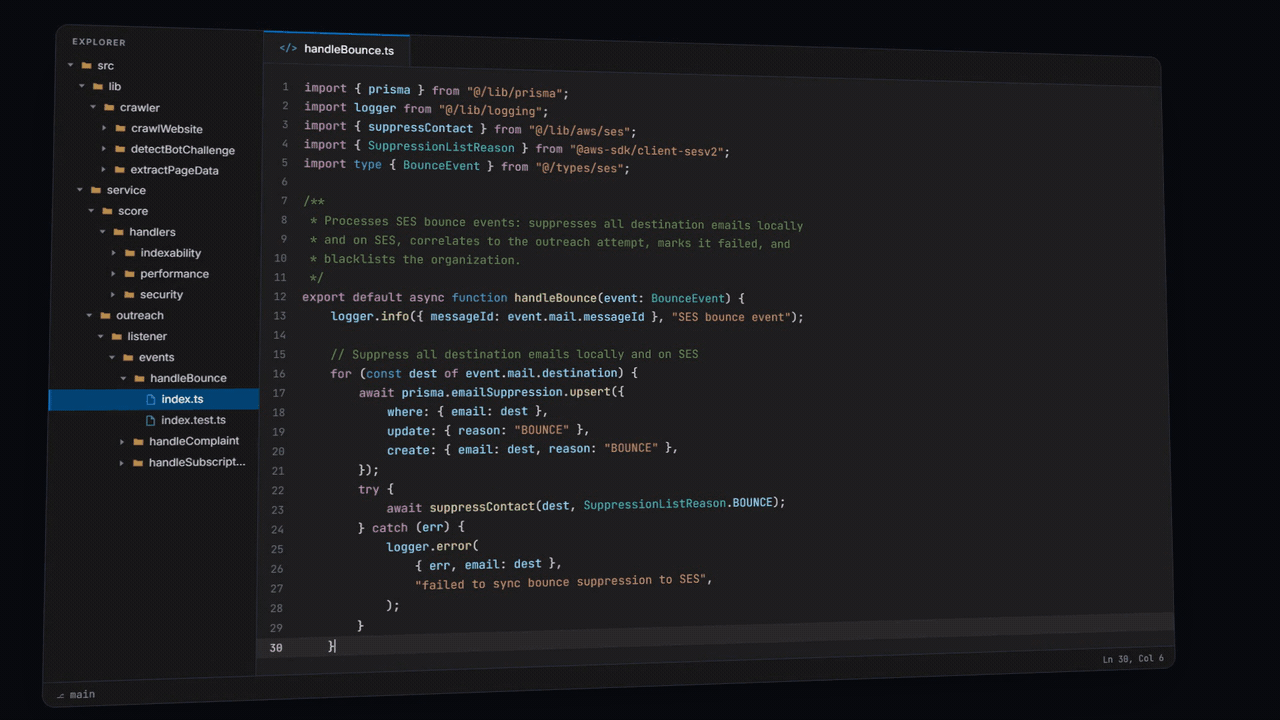
Let's review a real tetsukod.ai production bounce handler. We'll start by dissecting the file path.
src/service/outreach/listener/events/handleBounce/index.ts
Six folders deep. Each one informs the reader with greater detail, where exactly they are in the codebase and what the current module does.
src/service/outreach/— the outreach service. Every submodule here works with outreach.listener/— the inbound listener. Everything coming back from SES routes through here.events/— a grouping of SES event listeners. Each one handles a different email event.handleBounce/— the bounce handler. Itsindex.tsprocesses SES bounce events: suppresses every destination email locally and on SES, correlates the bounce to its outreach attempt, marks the attempt failed, and blacklists the organization so the sequence stops.index.ts— the handleBounce function. One single default export.
How does 1fpf affect code review?
1fpf stands for one function per file. It isn't a limit on file size. It's the shape your codebase takes when you've done the work upstream.
Traditional conventions would have you scrolling through 800 lines of code to understand the purpose of a module. With 1fpf, you read the folder names instead. Each folder is named after its default export — the function it holds.
This shifts the thinking upstream, and allows a reviewer to focus on higher level concepts rather than low level business logic.
Three rules of proper decomposition
You might have noticed how the entire bounce handler fits in under 100 lines of code. That's no accident. When you properly decompose your architecture, function bodies become small and concise - a focused surface where it's difficult for an agent to make a mistake. Once you've reached this stage of decomposition, you can generally trust an agent to work without having to read every single line.
So this begs the question: How does one achieve proper decomposition anyway?
1. Your data model must reflect reality
Your schema is the root of your architecture. A data model that doesn't match reality, mixes concerns and creates a system that can't grow.

2. Your folder structure must mirror the system
We covered this earlier — name your folders named after domain concepts, never technical ones. src/service/outreach/listener/events/handleBounce/, not helpers/email-utils/bounceHandler/.
The folder path orients the reader - layer by layer - to exactly the logical component the current module or submodule represents within the system.
3. Your types must be derived from the schema
Avoid rolling your own types. Instead, derive them directly from the schema. This ensures consistency and atomicity. When types are derived from your ORM, you lock the contract at the root layer, removing drift from the equation.

The PR you can merge in five minutes
Okay so now we have established that systems are designed in layers.. But how does this help us read an AI generated pull request?
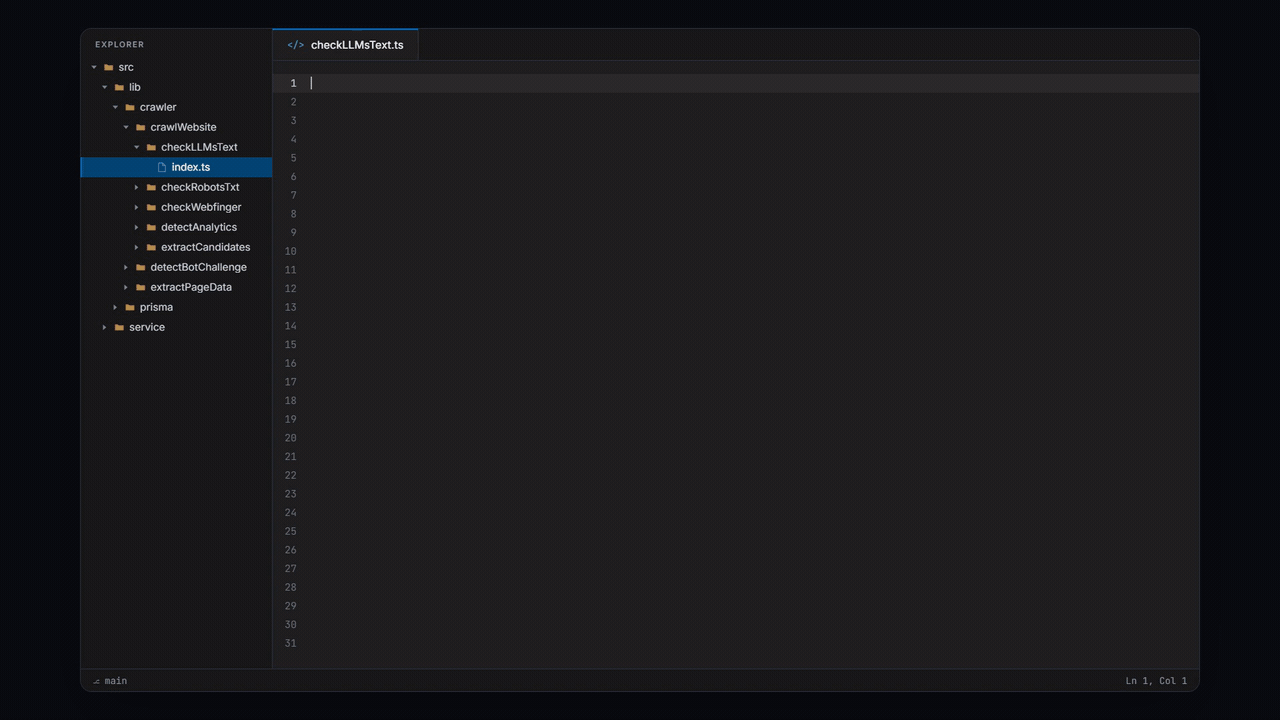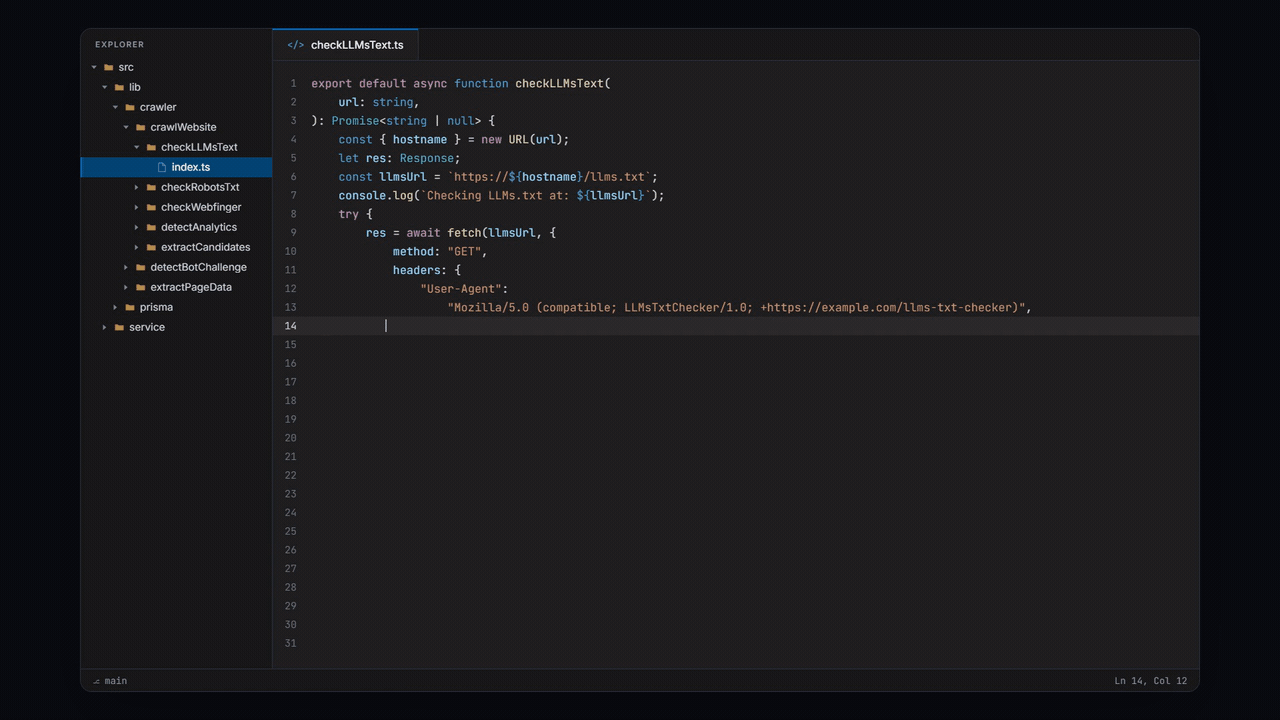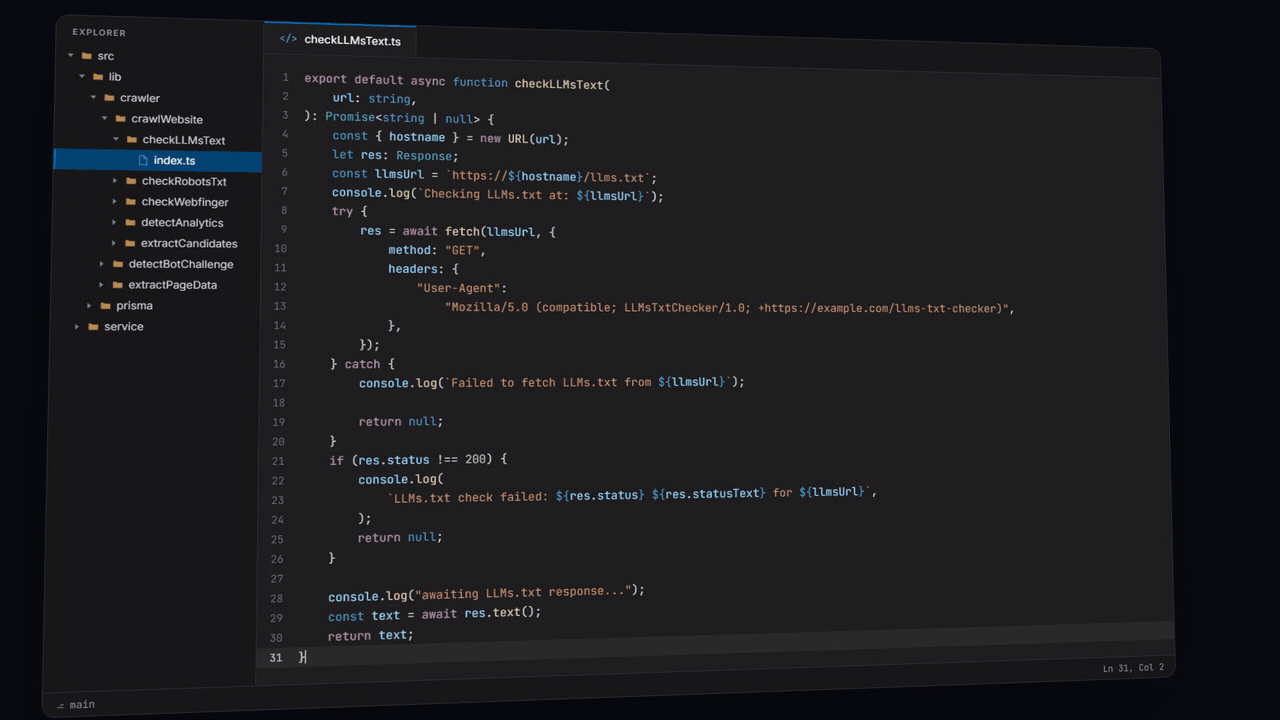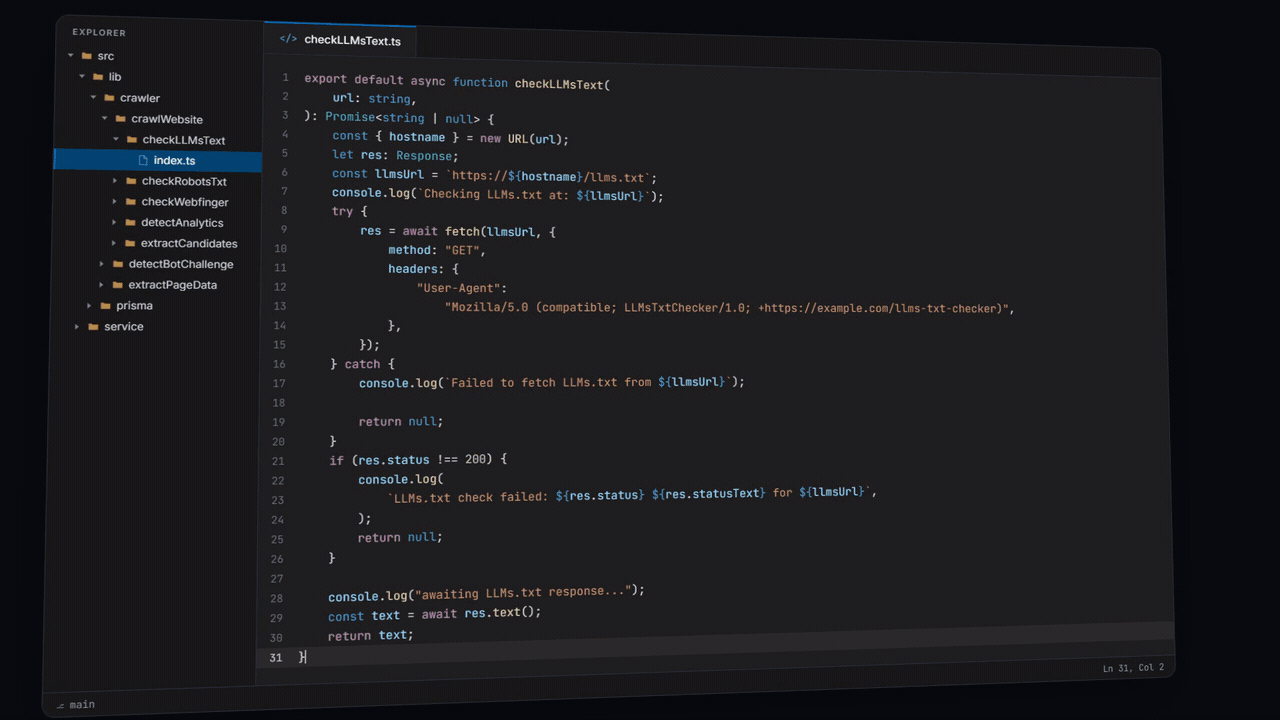
When a codebase follows these patterns, folder structure carries all the context a reader needs to understand the system. When you're reviewing a PR and the folder path reads: src/lib/crawler/crawlWebsite/checkLLMsText, you can be fairly certain of what's inside.
The function receives a url as input and parses the hostname, makes a call to the domain at /llms.txt and checks for a 200 status response. This is boilerplate code. It's not something an agent would generally get wrong.
Where this leaves you
When all these conditions are met, what you're left with is a codebase that reads itself. You understand what you ship and trust what you merge. The /1fpf skill is available for your coding agent to use right now but the methodologies go much deeper.
If you want to learn more about agentic engineering, system design, and 1fpf subscribe to my substack — Progressive Disclosure — where I dive deeper into the methodologies and frameworks I use every single day.
Take back control of your codebase. Follow along to learn how.
Want the /1fpf skill?
The /1fpf Claude Code skill teaches your agent how to carve a module into orchestrator + helpers — one function per file, types derived from the schema, folder names that narrate the control flow.
Get it exclusively at https://tetsukod.ai/skills/1fpf.
Subscribe to Progressive Disclosure to be notified whenever any new skills drop.